O cérebro lê chinês ou espanhol da mesma maneira que lê inglês?
Autores
Jovens revisores

Resumo
Hoje, há pelo menos 6.000 línguas faladas no mundo [1]. Essas línguas são representadas por uma variedade de sistemas de escrita chamados “ortografias”. As ortografias são os símbolos usados para representar a linguagem falada. Agora, enquanto lê este texto, você está olhando para um tipo de ortografia! Assim, uma ortografia consiste nos símbolos usados para registrar, em uma forma escrita, uma língua falada. No entanto, as ortografias diferem no tamanho da unidade de som que é representada por cada símbolo. Por exemplo, nas ortografias alfabéticas, como a inglesa, a espanhola e a russa, cada símbolo representa um som individual chamado fonema (por exemplo, o som de /b/ em “bom” é um fonema). Nas ortografias não alfabéticas, como a chinesa ou a cherokee, o símbolo representa uma unidade de som maior, como por exemplo uma sílaba (digamos,“pro” na palavra “projeto”). Hoje existem mais de 400 ortografias. Cada ortografia pode ser classificada como alfabética, como a inglesa, ou não-alfabética, como a chinesa. Neste artigo, aprenderemos primeiro sobre as características das diversas ortografias. Depois, usaremos essas características para procurar entender como diferentes sistemas de escrita afetam o processo de leitura. Em seguida, aprenderemos sobre as regiões do cérebro envolvidas na leitura.
Primeiro, vamos falar sobre as ortografias alfabéticas. Há vários alfabetos diferentes, que são usados para criar linguagens escritas. Por exemplo, o inglês usa o alfabeto latino, com 26 símbolos ou letras para representar a linguagem falada. O norueguês e o eslovaco também usam o alfabeto latino ou o mesmo conjunto de símbolos, mas o norueguês inclui três vogais não usadas no inglês (å, æ, ø) e o eslovaco recorre a uma série de acentos para indicar como uma letra é pronunciada (por exemplo, ó ou š), resultando no uso de 46 símbolos para representar a linguagem falada. Muitas línguas europeias usam o alfabeto latino, incluindo inglês, francês, espanhol, italiano, holandês, alemão, português, checo, eslovaco, húngaro, polonês, dinamarquês, galês, sueco, islandês, finlandês e turco [1].
Existem outros alfabetos que usam diferentes conjuntos de símbolos para representar a língua falada, mas ainda codificam a língua no nível de fonema. Esses alfabetos incluem o alfabeto cirílico, usado para os idiomas russo, búlgaro e ucraniano; o alfabeto devanagari, usado para o hindi, uma das línguas oficiais da Índia, o alfabeto grego, usado apenas para o idioma grego, e o alfabeto hangul, usado para o idioma coreano. Algumas línguas, tais como o servo-croata, usam tanto o alfabeto latino quanto o cirílico. Uma ortografia alfabética que contém apenas consoantes e não vogais é chamada de “abjad”. A ortografia arábica e a hebraica são às vezes classificadas como abjads porque as vogais, tradicionalmente, não são incluídas na escrita.
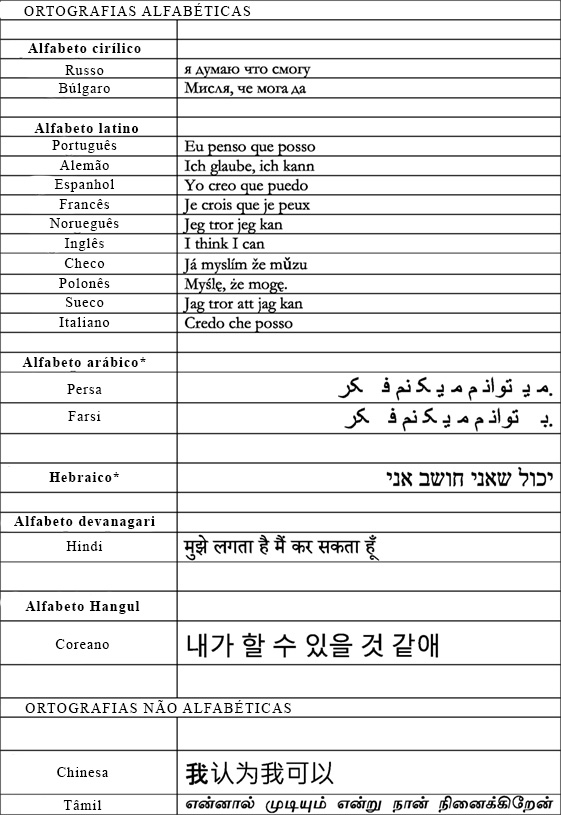
No entanto, hoje, frequentemente usamos acentos para mostrar onde uma vogal deveria estar, levando muitas pessoas a classificar o hebraico e o árabe como alfabetos, não abjads. Na Figura 1, você pode comparar diversas ortografias alfabéticas (e não alfabéticas) usadas para descrever a mesma declaração: “Eu acho que posso”.
As ortografias alfabéticas também diferem no modo como os fonemas (sons) e grafemas (símbolos ou letras) se combinam. Em algumas línguas, como a espanhola, a italiana e a alemã, quase todas as letras representam um único som. Quando cada letra é sempre pronunciada exatamente da mesma maneira, diz-se que o mapeamento é “consistente” e a ortografia é chamada de “superficial”. Em outras línguas, como o inglês e o dinamarquês, uma letra pode ter várias pronúncias, como os dois sons diferentes de /c/ em “circus”. Nesse caso, o mapeamento é considerado “inconsistente” e a ortografia é chamada de “profunda”. Assim, o espanhol é uma ortografia consistente ou superficial e o inglês é uma ortografia inconsistente ou profunda.
Embora nem todos concordem com a maneira de comparar as consistências entre letras e sons nos vários idiomas, os pesquisadores geralmente sustentam que o finlandês, o grego, o italiano, o espanhol, o alemão, o servo-croata, o turco e o coreano são ortografias relativamente superficiais ou consistentes, enquanto o português, o francês e o dinamarquês contêm mapeamentos mais inconsistentes entre fonemas e grafemas. O inglês é a língua mais inconsistente do mundo!
Agora, falemos sobre as ortografias não alfabéticas. As ortografias não alfabéticas representam a sílaba (por exemplo, cherokee, tâmil ou japonês kana) ou a unidade de significado de uma sílaba (como o chinês e o japonês kanji) com um símbolo. Do mesmo modo que nas ortografias alfabéticas, uma unidade de linguagem falada é representada por um símbolo, mas nas ortografias não alfabéticas essa unidade de linguagem falada é maior do que apenas um fonema.
O chinês costuma ser chamado de escrita pictográfica (língua composta de imagens) porque as pessoas pensam que os caracteres são imagens das palavras que representam. Na verdade, muito poucos caracteres chineses são realmente imagens das palavras que representam. Ao contrário, nessa escrita os símbolos representam uma unidade de pronúncia (uma sílaba), que é também uma unidade de significado (um morfema): portanto, o chinês é um sistema de escrita morfossilábico. Aproximadamente 80-90% dos caracteres chineses contêm igualmente o chamado radical fonético. Um radical fonético é apenas uma parte do caractere que fornece uma pista de como dizer a palavra. Você pode ver exemplos de chinês e tâmil na Figura 1.
Como vemos, há algumas coisas iguais em todas as ortografias e outras diferentes. Todas as ortografias representam uma linguagem falada com símbolos escritos. No entanto, a parte da linguagem oral que é codificada e a consistência dos mapeamentos entre sons e símbolos diferem entre as ortografias. A seguir, exploraremos como essas semelhanças e diferenças afetam as habilidades de leitura e veremos como o cérebro lê diferentes idiomas.
É mais difícil aprender a ler em algumas ortografias do que em outras?
A rapidez e a qualidade do aprendizado de leitura pelas crianças diferem entre os idiomas. Algumas dessas diferenças se devem às características do sistema de escrita [2].
Um amplo estudo comparou crianças que estavam aprendendo a ler em 14 ortografias alfabéticas diferentes e descobriu que, no final da 1ª série, as que aprendiam a ler em ortografias superficiais, como o espanhol, o finlandês e o grego, cometiam menos erros de leitura e liam mais rápido do que as que aprendiam a ler em ortografias mais inconsistentes, como o dinamarquês e o inglês [2]. Algumas das diferenças no aprendizado da leitura podem se dever ao fato de que as crianças aprendem de forma diferente nos vários países. Mas pesquisas apoiam decisivamente a ideia de que o aprendizado da leitura é mais fácil em ortografias consistentes do que em ortografias inconsistentes. Os leitores ingleses demoram mais para aprender a ler do que os de quase todas as outras ortografias alfabéticas e os leitores chineses demoram ainda mais [3].
As crianças apresentam diferentes problemas de leitura nas diferentes ortografias?
As crianças com grande dificuldade em aprender a ler podem ter um problema de aprendizagem conhecido como dislexia do desenvolvimento. Elas não são capazes de ler tão bem quanto as outras da mesma idade. Suas dificuldades com a leitura não se devem a ensino deficiente, a algum problema visual ou auditivo ou a outros distúrbios cerebrais. Acredita-se que cerca de 5% das crianças em todos os idiomas tenham sérios problemas de leitura.
Crianças com dislexia, em qualquer idioma, enfrentam dificuldades em converter símbolos escritos nos sons que eles representam [3]. Essa habilidade é chamada de decodificação fonológica. No entanto, o grau em que os problemas de decodificação fonológica interferem na leitura difere entre os idiomas.
Crianças com dislexia em ortografias consistentes, como o alemão, o espanhol e o italiano, conseguem ler palavras corretamente, mostrando que possuem boa habilidade de decodificação fonológica, mas tendem a ser leitores muito lentos. Em contraste, problemas com a decodificação fonológica afetam muito a leitura de ortografias inconsistentes, como o inglês. Crianças com dislexia em inglês tendem a cometer muitos erros ao ler palavras [3]. Crianças com dislexia em chinês, uma língua não alfabética, também apresentam problemas de decodificação fonológica, o que pode afetar a leitura.
Os leitores chineses que têm problemas com a decodificação fonológica podem não ser capazes de usar os radicais fonéticos existentes dentro de um caractere chinês como uma pista para ajudar na pronúncia dessa palavra. Mas, esse não é o principal problema para as crianças chinesas com dislexia. Em chinês, entender como o caractere representa o significado da palavra, habilidade chamada “percepção morfológica”, é um dos fatores mais importantes para a leitura, e crianças com dislexia costumam ter problemas nessa área [4]. Assim, a decodificação fonológica é importante para aprender a ler em chinês, mas provavelmente menos importante do que para aprender a ler em uma ortografia alfabética [3]. E, nas ortografias alfabéticas, os problemas de decodificação fonológica criam mais problemas de leitura em ortografias inconsistentes, como o inglês, do que nas consistentes, como o espanhol.
Vemos semelhanças e diferenças na leitura entre as ortografias. A rapidez e a qualidade do aprendizado de leitura das crianças depende parcialmente das características da ortografia. A decodificação fonológica é importante para a leitura em todas as ortografias, mas em diferentes graus, dependendo do sistema de mapeamento usado em uma determinada ortografia. O que essas semelhanças e diferenças significam em termos do modo como o cérebro lê as diferentes ortografias?
Existe no cérebro uma rede universal para a leitura nas diferentes ortografias?
Embora existam diferenças na rapidez com que as crianças aprendem a ler, e nos problemas de leitura que elas enfrentam em diferentes ortografias, há motivos para acreditar que a leitura em todos os idiomas usa algumas das mesmas áreas do cérebro. O primeiro passo para se ler em qualquer idioma é olhar e analisar a palavra impressa. Além disso, todas as ortografias representam a linguagem falada, o que sugere que a decodificação fonológica, ou determinação de quais sons os símbolos representam, é necessária para todas as leituras.
Estudos de imagens do cérebro, em que equipamentos especiais são usados para tirar “fotos” desse órgão, podem nos dizer muito sobre como o cérebro lê diferentes ortografias. As técnicas de imagem cerebral mais comuns usadas para explorar a leitura de idiomas são chamadas de imagem de ressonância magnética funcional (IRMF) e tomografia por emissão de pósitrons (TEP). Esses dois exames criam imagens do cérebro quando ele está trabalhando em uma tarefa, o que permite aos pesquisadores verem quais áreas do cérebro são usadas quando se lê. Empregando essas ferramentas para comparar a atividade cerebral quando uma pessoa está lendo diferentes ortografias, os pesquisadores podem distinguir as regiões do cérebro que são usadas quando estamos lendo todas as ortografias das que só são usadas quando estamos lendo ortografias específicas.
Um grupo de pesquisadores identificou três áreas no hemisfério (ou lado) esquerdo do cérebro que são usadas durante a leitura em todas as ortografias estudadas [5]. Esses pesquisadores combinaram os resultados de 43 estudos diferentes de IRMF e TEP de leitura em vários idiomas, incluindo inglês, francês, italiano, alemão, dinamarquês, chinês, japonês kana e japonês kanji.
As três regiões do cérebro usadas em todas as ortografias eram uma região no topo do lobo temporal esquerdo em direção à parte posterior do cérebro chamada área temporal-parietal, que pode estar envolvida na decodificação fonológica, uma região ao longo da parte inferior do lobo frontal esquerdo chamado de circunvolução frontal inferior, e a área de formação visual de palavras (AFVP). Esta é uma região da circunvolução fusiforme localizada ao longo da parte inferior dos lóbulos temporal e occipital, no hemisfério esquerdo do córtex cerebral (ver Figura 2). Acredita-se que a AFVP seja usada apenas quando vemos letras e palavras escritas, não quando vemos objetos, e esteja envolvida na leitura em todas as ortografias estudadas até agora [6].
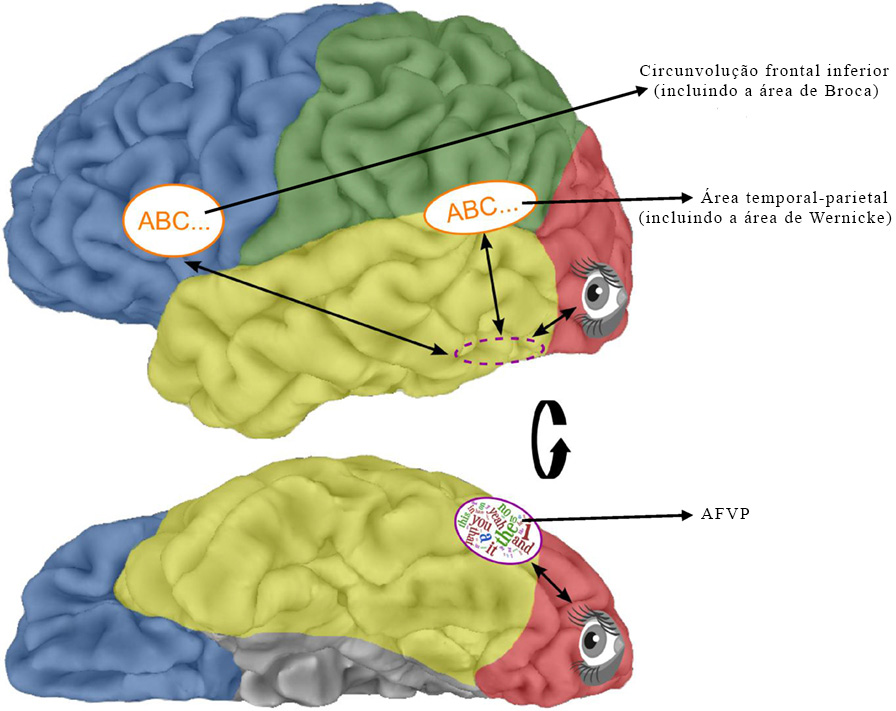
A área da formação visual de palavras (AFVP) é a região do cérebro devotada exclusivamente à leitura. Podemos ver a AFVP (oval roxa com palavras) na figura inferior, vista de baixo, do hemisfério esquerdo do cérebro. Na figura de cima, a oval roxa tracejada indica onde a AFVP estaria se pudéssemos vê-la de lado. Imagem de Kassuba e Kastner [7]. Copyright © 2015 Kassuba and Kastner.
O mesmo grupo de pesquisadores identificou também várias áreas do cérebro usadas somente quando uma ortografia específica está sendo lida. Por exemplo, a circunvolução fusiforme no hemisfério (lado) direito do cérebro estava ativa durante a leitura do chinês, mas não de outras línguas. Esse padrão de atividade cerebral significa que, ao ler chinês, a circunvolução fusiforme nos hemisférios esquerdo e direito é usada; mas, ao ler qualquer uma das ortografias alfabéticas, apenas se usa a área fusiforme do hemisfério esquerdo, a AFVP. Os pesquisadores acreditam que as regiões do cérebro usadas apenas na leitura do chinês podem ajudar a fazer conexões entre o significado e os sons de uma palavra, bem como a ler o desenho em forma de quadrado dos caracteres chineses.
A leitura é uma tarefa complexa e uma habilidade relativamente nova para a espécie humana. Ao que tudo indica, algumas regiões do cérebro, com o tempo, se adaptaram à leitura ou evoluíram nessa habilidade. Pesquisas mostram que há algumas áreas comuns do cérebro envolvidas na leitura dos vários idiomas, áreas que promovem o reconhecimento visual dos símbolos e a identificação de quais sons os símbolos representam. No entanto, também existem áreas especializadas do cérebro que abrigam as habilidades específicas necessárias para ler uma ortografia específica. A maioria dos estudos de pesquisa até o momento se concentrou em ortografias alfabéticas, principalmente as baseadas no alfabeto latino. Mais estudos são necessários para explorar a leitura em outras ortografias se quisermos saber com certeza se o cérebro lê todos os idiomas da mesma maneira.
Glossário
Morfema: Raízes ou partes de palavras que podem ser adicionadas ou removidas de uma palavra para alterar seu significado. Em inglês, um morfema pode ser uma palavra (por exemplo, build), um prefixo (por exemplo, o re na palavra rebuild), um sufixo (por exemplo, o er na palavra builder) ou uma inflexão gramatical (por exemplo, o s para o plural na palavra builders).
Ortografia: Símbolos usados para representar uma linguagem falada.
Decodificação fonológica: Conversão de símbolos escritos nos sons que eles representam.
Referências
[1] Comrie, B., ed. 2009. The World’s Major Languages. 2nd ed. New York, NY: Routledge.
[2] Seymour, P. H. K., Aro, M. e Erskine, J. M. 2003. “Foundation literacy acquisition in European orthographies.” Br. J. Psychol. 94:143–74. DOI: 10.1348/000712603321661859.
[3] Brunswick, N. 2010. “Unimpaired reading development and dyslexia across different languages.” Em: Reading and Dyslexia in Different Orthographies, orgs. N. Brunswick, S. McDougall e P. de Mornay Davies, 131–54. New York, NY: Psychology Press.
[4] Perfetti, C., Cao, F. e Booth, J. 2013. “Specialization and universals in the development of reading skill: how Chinese research informs a universal science of reading.” Sci. Stud. Read. 17:5–21. DOI: 10.1080/10888438.2012.689786.
[5] Bolger, D. J., Perfetti, C. A. e Schneider, W. 2005. “Cross-cultural effect on the brain revisited: universal structures plus writing systems variation.” Hum. Brain Mapp. 25:92–104. DOI: 10.1002/hbm.20124.
[6] Carreiras, M., Armstrong, B. C., Perea, M. e Frost, R. 2014. “The what, when, where, and how of visual word recognition.” Trends Cogn. Neurosci. 18:90–8. DOI: 10.1016/j.tics.2013.11.005.
[7] Kassuba, T. e Kastner, S. 2015. “The reading brain.” Front. Young Minds. 3:5. DOI: 10.3389/frym.2015.00005.
Citação
Conrad, N. (2016). “Does the brain read Chinese or Spanish the same way it reads English?” Front. Young Minds. 4:26. DOI: 10.3389/frym.2016.00026.
Este é um artigo de acesso aberto distribuído sob os termos da Creative Commons Attribution License (CC BY). O uso, distribuição ou reprodução em outros fóruns é permitido, desde que o(s) autor(es) original(is) e o(s) proprietário(s) dos direitos autorais sejam creditados e que a publicação original nesta revista seja citada, de acordo com a prática acadêmica aceita. Não é permitido nenhum uso, distribuição ou reprodução que não esteja em conformidade com estes termos.
Encontrou alguma informação errada neste texto?
Entre em contato conosco pelo e-mail:
parajovens@unesp.br


